Tensorflow 2.0 / Keras - LSTM vs GRU Hidden States
I was going through the Neural Machine Translation with Attention tutorial for Tensorflow 2.0. Having gone through the verbal and visual explanations by Jalammar and also a plethora of other sites, I decided it was time to get my hands dirty with actual Tensorflow code.
I had previously done a bit of coding related to CNNs for my Final Year Project, but this was my first experience with RNNs. I had learnt the theory of RNNs and its mainstream relatives, LSTM and GRU, but this was my first time looking at the code. The first thing that got me stumped was the hidden states in the Encoder class.
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(self.enc_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))The key here are the two arguments, return_sequences and return_state, which were both set to True. This will enable us to retrieve the output state and hidden state. Initially, I thought that the output state and the hidden state were the same. This was because my knowledge of LSTM and GRU were lacking.
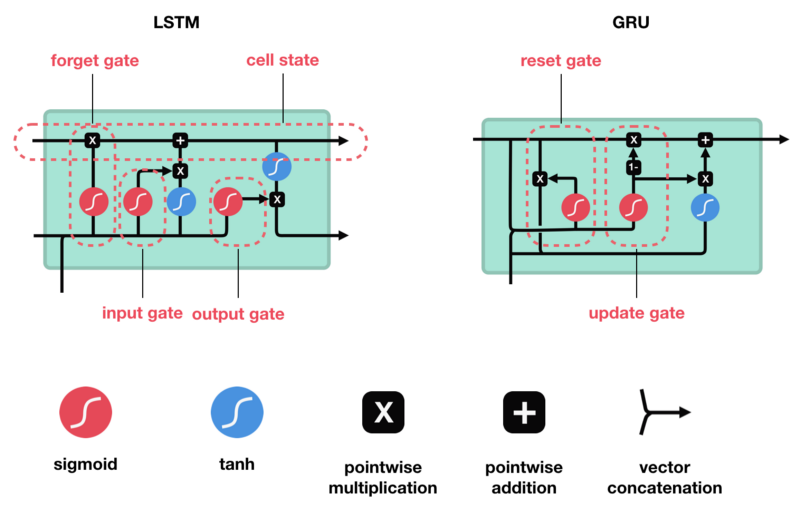
As we can see, LSTM has two outputs, the cell state on top, and the hidden state at the bottom. Meanwhile, GRU only has one output, the hidden state. After going through Keras’ documentation (because Tensorflow 2.0’s documentation has not been fully updated), it is stated that:
Output shape
-
if return_state: a list of tensors. The first tensor is the output. The remaining tensors are the last states, each with shape (batch_size, units). For example, the number of state tensors is 1 (for RNN and GRU) or 2 (for LSTM).
-
if return_sequences: 3D tensor with shape (batch_size, timesteps, units).
A minimal example is available at Understand the Difference Between Return Sequences and Return States for LSTMs in Keras by Jason Brownlee. The code below is extracted from the post linked above and is for LSTM.
from keras.models import Model
from keras.layers import Input
from keras.layers import LSTM
from numpy import array
inputs1 = Input(shape=(3, 1))
lstm1, state_h, state_c = LSTM(1, return_sequences=True, return_state=True)(inputs1)
model = Model(inputs=inputs1, outputs=[lstm1, state_h, state_c])
data = array([0.1, 0.2, 0.3]).reshape((1,3,1))
print(model.predict(data))The output for that piece of code would be:
[array([[[-0.02145359],
[-0.0540871 ],
[-0.09228823]]], dtype=float32),
array([[-0.09228823]], dtype=float32),
array([[-0.19803026]], dtype=float32)]
However, when we use GRU, keep in mind that it has no cell state. It only has a hidden state.
from keras.models import Model
from keras.layers import Input
from keras.layers import GRU
from numpy import array
inputs1 = Input(shape=(3, 1))
output, hidden = GRU(1, return_sequences=True, return_state=True)(inputs1)
model = Model(inputs=inputs1, outputs=[output, hidden])
data = array([0.1, 0.2, 0.3]).reshape((1,3,1))
print(model.predict(data))The output for that piece of code would be:
[array([[[-0.02145359],
[-0.0540871 ],
[-0.09228823]]], dtype=float32),
array([[-0.09228823]], dtype=float32)]Notice that the second array is the final hidden state, which is the same as the last value of the first array. The output from the GRU also has one less array because it does not have a cell state unlike LSTM.
Now, pardon me as I get back to completing the tutorial.